Clik here to view.

A few months ago we began a series of posts on this blog where we explained how you can train an Artificial Intelligence (AI) to eventually win certain games. If this subject intrests you, we invite you to watch our webinars “Dominate classic videogames with OpenAI and Machine Learning” where we explain everything you need to know about OpenAI Gym, from its installation to its functions, as well as showing examples with Python and simple techniques of Reinforcement Learning (RL). It was two-part series that began on April 24 and concluded on May 29.
Before moving forwards with these two episodes, we encourage you to read the following posts (in Spanish):
- Part 1. Cómo entrenar a tu Inteligencia Artificial jugando a videojuegos, preparando la “rejilla de juegos”
- Part 2. Cómo entrenar a tu Inteligencia Artificial jugando a videojuegos, observando el entorno
- Part 3. Cómo entrenar a tu Inteligencia Artificial jugando a videojuegos, resolviendo CartPole con Random Search
- Part 4. Cómo entrenar a tu Inteligencia Artificial jugando a videojuegos. Aprende Q-Learning con el juego “Taxi”, parte 1 de 2
- Part 5. Cómo entrenar a tu Inteligencia Artificial jugando videojuegos. Aprende Q-Learning con el juego “Taxi”, parte 2 de 2
In these posts, you can find an introduction to OpenAI and its Universe and Gym libraries, and then you can develop simple solutions for well-known environments such as CartPole and Taxi. These articles will help you to install the environment and the necessary libraries, as well as establishing the foundations that will help you in the following posts.
In this new series, we’ll continue with OpenAI but this time we’re going to take on bigger challenges, with regards to the complexity of the game and the design of the AI agent (using Reinforcement Learning techniques). Our aim is to offer an introduction to the training of an AI that is capable of taking on these harder videogame environments by following a strategy of trial and error.
Our base for training will be Atari’s classic videogameBreakout, but the solutions that we develop can be extrapolated to other games with similar characteristic. Although we have increased the difficulty of the environment, we are going to need a platform that isn’t too complex. This simply means that there aren’t too many moving objects to analyze and that the sequence of movement is simple (left, right, shoot). Within these limitations we can include classics such as Space Invaders and Pac-Man.
Clik here to view.

These arcade games can be played on the Atari 2600 console, developed in 1977 and which ended up seeing successful sales for over a decade, and marked the teenage years of many of us. The simplicity of the game environments developed for this console has allowed these “worlds” to become platforms for the study and application of AI and Machine Learning techniques. This simplicity each frame of a game can be defined by its state in a relatively manageable observation space, with a limited amount of actions.
As mentioned earlier, the game we have decided to use for our Proof of Concept (PoC) is Breakout. This classic arcade game was created in 1976 by Nolan Bushnell and Steve Bristow but initially built by Steve Wozniak. The aim of the game is to break all the bricks that fill the upper half of the screen with a ball that bounces of your moveable paddle. The paddle can move to the left and right, within the game limits.
Clik here to view.
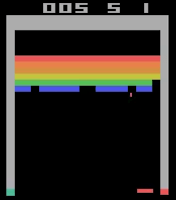
The player tries to bounce the ball back towards the bricks, destroying them one by one, and making sure that the ball doesn’t fall off the lower part of the screen (which causes you to lose a life). The game resets each time all the bricks have been destroyed or whrn the player loses all of the five lives they start with.
Thanks to the large number of supported environments, you can see the full list here, we will again use OpenAI and Gym. This time it will be supplied with screenshots from the game so that before we start, it can identify and locate the pixels of the screen that correspond to different elements of the game (such as the position of the ball, the paddle etc).
The Gym environment that we have used is called Breakout-v0 and has the following characteristics:
- An observation space (env.observation_space) that can be represented by a state of play. It is an array with dimensions (210, 169, 3) which represents the pixel values of an image in the game. The third dimension is reserved for the defined RGB values of each pixel for a 128 bit color palette.
- The action space (env.action_space.n) for this game is defined as a group of four integers [0, 1, 2, 3]. The relationship between these integers and the allowed actions can be obtained using (env.unwrapped.get_action_meaning), which returns [‘NOOP’, ‘FIRE’, ‘RIGHT’, ‘LEFT’].
Clik here to view.
The following steps can summarize the interaction with the OpenAI Gym: load the environment from the library; obtain an initial random state; apply a certain action to the environment that is derived from a rule; this action will take place in a new game state; receive a reward after applying the action, such as an indicator if the game has finished.
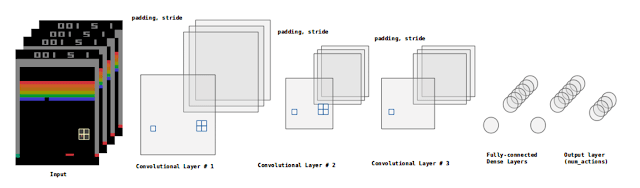
By training an AI in environments such as Breakout with techniques such as “Random Search”, we recognize that is it an immeasurable task, especially when the agent is given game states that are larger and more complex. Therefore we need our agent to use an appropriate set of actions that allows us to approximate the Q(s,a) function, which maximizes the reward “a” by applying a given action “s” to the state. But, how can we deal with the complexity that comes when combining different states and approximate this function? We can do it by using Deep Neural Networks equipped with Q-Learning algorithms, most commonly known as Deep Q-Networks (DQN).
For this type of training, the Neural Networks to use are called Convolutional Neural Networks. Throughout the history of Deep Learning, these networks have proven to behave excellently when recognizing and learning patterns based on images. These networks take the values of pixels of the frames that serve as inputs. The representations of these entries become more abstract as they pass through the “architecture” (its various layers) and the results is a dense final layer which shows a number of outputs that is equal to the action space of the environment (4 in the case of Breakout-v0).
Clik here to view.
Optimizing a Neural Network is a difficult task, since it is highly dependent on the quality and quantity of the data that is used to train the model. The difficulty in optimizing the network is also a result of the architecture itself, since a larger number of layers and greater “dimensionality” requires the optimization of a larger number of weights and biases.
As a reminder, the Q(s,a) function is defined as:
Clik here to view.
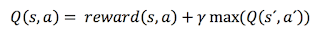
If we know the Q(s,a) function perfectly, one could immediately know which action to carry out based on a defined policy:
Clik here to view.
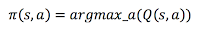
The Neural Network will try to predict its own output by repeatedly using this formula that is aimed at modifying the Q(s,a) function. However, what can guarantee that we can make the Q function converge towards the truth by taking samples of a decision making policy? Unfortunately, nothing can save us from a function that never converges towards the optimum. There are however, technical differences that will allow this function to correctly approximate, but we will explain those in the second part of this series.
During the training of these types of architectures, the most convenient strategy is to give our algorithm a combination of “pre-processed” initial states, which it can use to obtain a beneficial action for the agent, that will recognize the “reward” of this action, and the following state of the environment, and then continue to feed the model in this way.
Now that we have a foundation of Deep Neural Networks and Q-Learning, in the following post we will present the results of our own training for Breakout and Space Invaders. Also, we will give more details about the implementation of the model’s architecture, the strategies used to reach the solution and the relevant tasks of prep-processing images that make the network more efficient. Our model will be a DQN built using the TensorFlow library.
Right now we are immersed in training this model, and below you can see a preview of the current capabilities of our agent:
As you can see, in one episode our AI is already capable of scoring 101 points! It’s been able to achieve this after being trained on over 1900 episodes and having processed almost 2.5e7 states during one week of training. We’re going to give the model more training time so that in the next article we can show you a video of how our agent is capable of destroying all the bricks before losing five lives, as well as another video of the model training in Space Invaders.
Written by Enrique Blanco (CDO Researcher) and Fran Ramírez (Security Researcher at Eleven Paths)
We look forward to seeing you in the next post!
Don’t miss out on a single post. Subscribe to LUCA Data Speaks.
The post Deep Learning vs Atari: train your AI to dominate classic videogames (Part I) appeared first on Think Big.