Clik here to view.

We are taking another step in our learning of Python by studying what the modules are, and, in particular the libraries. We will see what purpose some of them serve and lean how to import and use them.
What are the modules?
The modules are the form in which Python stores definition (instructions or variables) in an archive, so that they can be used after in a script or in an interactive instance of the interpretation (as in our case, Jupyter Notebook). Thus, we don’t need to return to define them every time. The main advantage of Python allowing us to separate a program into modules is, evidently, that we are able to reuse them in other programmed modules. For this, as we will see further on, it will be necessary to import the modules that we want to use. Python comes with a collection of standard modules that we can use as a base for a new program or as examples from which we can begin to learn.
Python organises the modules, archives .py, in packages, that are no more than folders that contain files .py (modules), and an archive that starts with the name _init_.py. The packages are a way of structuring the spaces by names of Python using ´names of modules with points´. For example, the number of the module A.B designates a submodule called B in a package called A. Just as the use of modules prevents the authors of different modules from having to worry about the respective names of global variables, the use of named modules with points prevents the authors of packages of many modules, such as NumPy or the image library of Python (Python Imaging Library or PIL), from having to worry about the respective names of modules.
└── paquete
├── __init__.py
├── modulo1.py
├── modulo2.py
└── modulo3.py
To import a module, use the instruction ´Import´´, following with the name of the package (if applicable) more the name of the module (without the .py) that you wish to import. If the routes (or what are known ´namespace´) are large, you can generate an alias by modifying ´as´:
The modules should be imported at the start of the program, in alphabetical order and, first the ones of Python, then those of the third party, and finally, those of the application.
The standard Python library
Python comes with a library of standard modules, in which we can find all the information under The Python Standard Library. To learn about syntax and semantics, it will also be good to have to hand The Python Language Reference. The standard library is very large and offers a great variety of modules that carry out functions of all kinds, from written modules in C that offer access to system functions like access to files (file I/O).
Python installers for platforms such as Windows, normally include a complete standard library, including some additional components. However, Python installations using packages will require specific installers.
A stroll through the standard library
The standard library offers a large variety of modules that carry out all times of functions. For example, the module OS offers typical functions that allow you to interact with the operative system, like how to tell in which directory you are, change directory, find help functions, the maths module that offers trigonometry functions, logarithms, statistics etc. There are also modules to access the internet and process protocols with urillib.request, to download data in a URL and smtplib, to send emails; or modules such as datetime, that allow you to manage dates and times, modules that allow you compress data, or modules that measure returns.
We don´t include examples so we don’t drag ourselves out too much, but if you´re really interested in learning, we recommend you test these modules one by one) from the Python Shell, or through Jupyter) with this small walk through the standard library that you can find in official Python documentation.
Virtual environments
However, the applications of Python often use packages and modules that don´t form part of the standard library, in fact Python is designing a way to facilitate this interoperability. The problem in which we find ourselves, common in the environment of open coding, is that applications frequently need a specific version of the library, because that application requires that a particular bug has been fixed or that the application has been written using an outdated version of the library interface.
This means that it may not be possible that Python installations complies with the requirements of all the applications. If application A needs version 1.0 of a particular module and application B needs version 2.0, there requirements are therefore conflicting and to install the version 1.0 or 2.0 will stop one of the applications working. The solution to this problem is to create a virtual environment, a directory that contains a Python installation from a particular version, moreover from one of the many additional packages. In this way, different applications can use different virtual environments. To resolve the example of conflicting requirements cited previously, application A can have its wen virtual environment with version 1.0 installed, whilst application B has its own virtual environment with the version 2.0.
Non-standard libraries
Given that the objective of our example is to carry out an experiment into the application of Machine Learning with Python to a determined dataset, we will need something more than the standard libraries that, even though offers us some mathematical functions, leaves us a little short. For example, we will also need modules that allow us to work with the visualisation of the data. We will get to know what are the most common in data science:
- NumPy : Acronym of Numerical Python. Its most powerful characteristics are that its able to work with an array of matrices and dimensions. It also offers basic lineal algebraic functions, transformed to Fourier, advanced capacities with random numbers, and integration tools with other languages at a basic level such as Fortran, C and C++.
- SciPy: Acronym of Scientific Python. SciPy is constructed around the library NumPy. It is one of the most useful with its grand variety of high-level modules that it has around science and engineering, as a discrete Fourier transformer, lineal algebra, and optimisation matrices..
- Matplotlib: is a graphic library, from histograms to lineal graphs or heat maps. It can also use Latex commands to add mathematical expressions to graphs.
- Pandas: used for operations and manipulations of structured data. It’s a recently added library, but its vast utility has propelled the use of Python in the scientific community.
- Scikit Learn formachine learning: Constructed on NumPy, SciPy and matplotlib, this library contains a large number of efficient tools for machine learning and statistic modelling, for example, classification algorithms, regression, clustering and dimensional reduction.
- Statsmodels: for statistic modelling. It’s a Python model that allows users to explore data, make estimations of statistic models, and carry out test statistics. It offers an extensive list of descriptive statistics, test, graphic functions etc for different types of data and estimators.
- Seaborn: based in matplotlib, it is used to make graphs more attractive and statistical information in Python. Its objective is to give greater relevance to visualisations, within areas of explorations and interpretation of data.
- Bokeh: allows the generation of attractive interactive 3D graphs, and web applications. It is used for fixing applications with streaming data.
- Blaze: it extends the capacity of NumPy and Pandas to distributed data and streaming. It can be used to access a large number of data from sources such as Bcolz, MongoDB, SQLAlchemy, Apache Spark, PyTables etc
- Scrapy: used to track the web. It’s a very useful environment for obtaining determined data owners. From the home page url you can ´dive´ into different pages on the site to compile information.
- SymPy: it is used for symbolic calculation, from arithmetic, to calculus, algebra, discrete mathematics and quantum physics. It also allows you to format the results in LaTeX code.
- Requests for accessing the web: it works in a similar weay to the standard library yrllib2, but its much simpler to code.
And now we suggest you do a simple exercise to practice a little. It consists of verifying versions of the Anaconda library that we have installed. On Anaconda´s web page, we can see this diagram showing the different types of available libraries (IDEs for data science, analytics, scientific calculations, visualisation and Machine Learning. As you can see, two libraries appear that we have not talked about, Dask and Numba. Thus, we must also investigate their use, and also check out which versions Anaconda has installed for us.
Clik here to view.
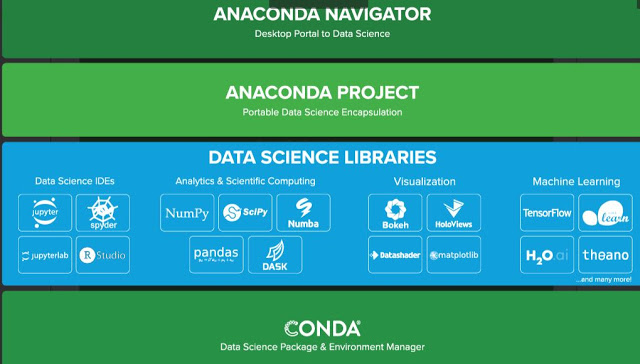
For that, you don’t need to do anything more than write in your Jupyter notebook, or copy and paste the following commands, (with a slight modification for the libraries that don’t show).
With this post we now have everything prepared to start the Machine Learning experiment. In the next one, we will start downloading the data, and the explorative analysis. We´re nearly there!
All the posts in this tutorial here:
- Dare with Python: An experiment for all (intro)
- Python for all (1): Installation of the Anaconda environment.
- Python for all (2): What are the Jupiter Notebook ?. We created our first notebook and practiced some easy commands.
- Python for all (3): ScyPy, NumPy, Pandas…. What libraries do we need?
- Python for all (4): We start the experiment properly. Data loading, exploratory analysis (dimensions of the dataset, statistics, visualization, etc.)
- Python for all (5) Final: Creation of the models and estimation of their accuracy
Don’t miss out on a single post. Subscribe to LUCA Data Speaks.
You can also follow us on Twitter, YouTube and LinkedIn
The post Python for all (3): ScyPy, NumPy, Pandas…. What libraries do we need? appeared first on Think Big.